Mind Meets Machine
(All datas anonymized and used with permission.)
Language is a powerful tool for expressing thoughts, emotions, and knowledge. Its structured yet flexible nature makes it ideal for human communication but a challenge for machines to process.
NLP (Natural Language Processing) addresses this, enabling machines to interpret and generate language by combining linguistic principles like syntax and semantics with machine learning techniques. Models like BERT (Bidirectional Encoder Representations from Transformers) have revolutionized NLP by understanding context deeply, capturing nuances in meaning, and making significant strides in tasks like text classification, question answering, and sentiment analysis.
Despite these advancements, language remains complex. Words change meaning with context, grammar adapts to cultural nuances, and implicit intentions demand sophisticated understanding. NLP’s goal is to harness these intricacies, turning raw data into actionable insights and transforming human-machine interaction.
How can we determine if this is a compliant response?
Determining whether a response is compliant or non-compliant exemplifies the challenges of understanding natural language. Our thesis explores how to identify these responses using artificial intelligence, with a specific focus on schizophrenia patients’ answers to clinical questions.
Through this work, we delve into the intersection of NLP and healthcare, exploring how machines can better comprehend the nuances of human responses in a medical context.
Problem
Determining the compliance status of responses lies at the core of this thesis. The primary aim is to evaluate and predict whether the answers provided by a schizophrenia patient are compliant or non-compliant using artificial intelligence. Another goal of the thesis is to assess how consistent these AI-driven predictions are with the evaluations made during a psychologist’s examination. Additionally, differing outcomes are compared, and their underlying reasons are interpreted to provide further insights.
Challenge
NLP’s complexity lies in understanding language’s nuanced meanings. For instance, “I need help with my medication” and “medication makes me feel worse” both mention “medication” but differ entirely in intent and implication. Keyword detection alone, like spotting “medication,” can’t capture this distinction. For example, “I never forget my medication” suggests compliance, while “I only take it when I feel like it” indicates non-compliance. Machine learning algorithms address this challenge by interpreting context, intent, and deeper meanings, enabling accurate classification beyond surface-level patterns.
Data Collection Process
Since January, audio recordings have been collected from 146 schizophrenia patients attending the Neurology Outpatient Clinic. This was done with the patients’ informed consent and after obtaining the necessary approvals from ethics committees. The patients were administered a custom-designed 16-question scale, which was carefully developed through in-depth research by a team of expert physicians. The English version of the questions in the scale includes the following:
After obtaining the audio recordings, they were transcribed into text using Whisper AI. We utilized a locally deployed open-source Whisper AI model with diarization capabilities. This model allowed us to distinguish between the voices of the doctor and the patient during the examination. It was then converted into the following format with the help of GPT-4:
Data Labeling
The data was labeled by a psychologist who read transcriptions. Psychologist was asked to classify each response as compatible or incompatible based on the following criteria:
- Compatible: The patient’s response is coherent, relevant, and directly addresses the question asked by the doctor.
- Incompatible: The patient’s response is incoherent, irrelevant, or does not directly address the question asked by the doctor.
Here’s how a single data point might look in dataset:
| QId | Question | Answer | Label |
|---|---|---|---|
| 1 | İlaçlarınızı ne sıklıkla alıyorsunuz? | Günde 3 defa | Compatible |
| 3 | İlaçların yan etkisi var mı? | İlaçların yan etkisi var galiba. | Incompatible |
Data Preprocessing
Removing Punctuation
Lowercasing
Handling Stop Words
Not necessary for BERT models.
Handling Special Characters
Choosing the Right BERT Model for Turkish
We use the dbmdz/bert-base-turkish-cased model, which is pre-trained on Turkish text.
Creating Datasets and Data Loaders
We tokenize the text data and create PyTorch datasets and data loaders.
Fine-Tuning BERT
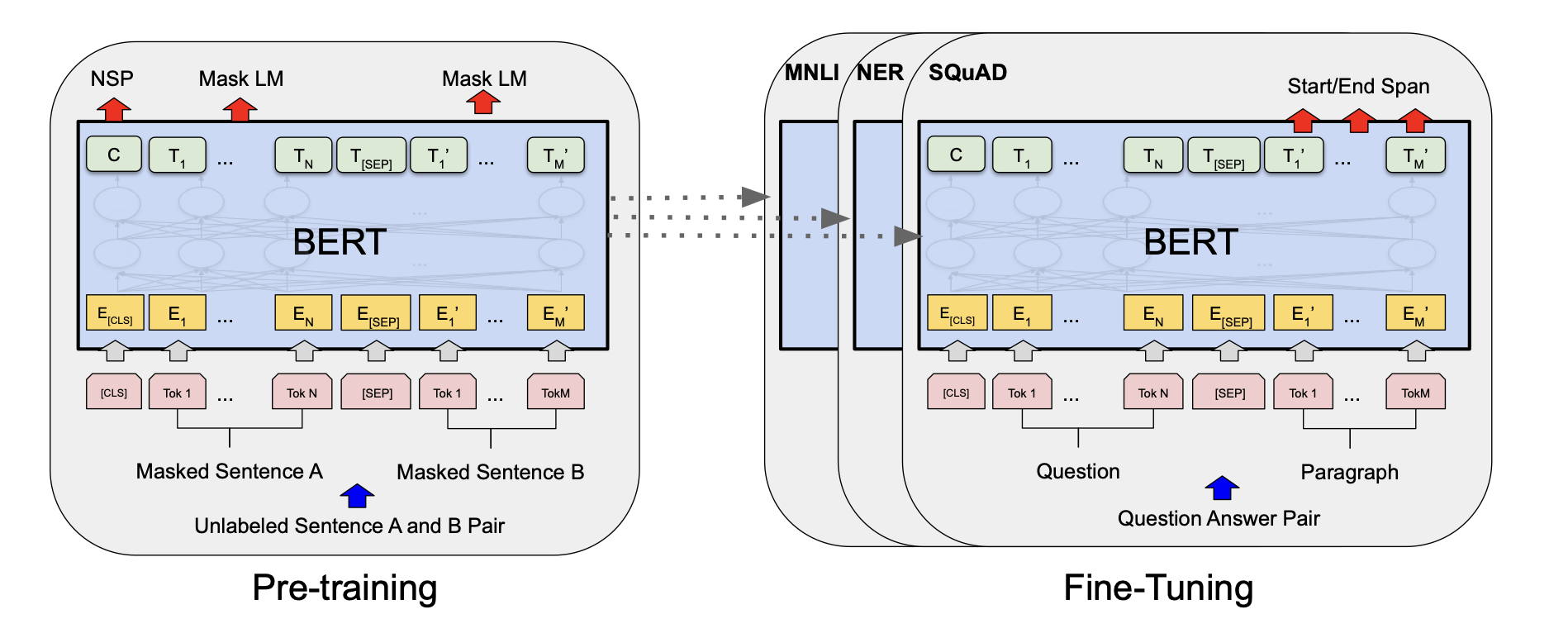
Fine-tuning BERT is straightforward due to its self-attention mechanism, which supports single or paired text tasks by adjusting inputs and outputs. Instead of independently encoding text pairs followed by cross-attention, BERT simplifies this by using self-attention on concatenated text pairs, inherently capturing bidirectional cross-attention.
We set up the optimizer, learning rate scheduler, and train the model.
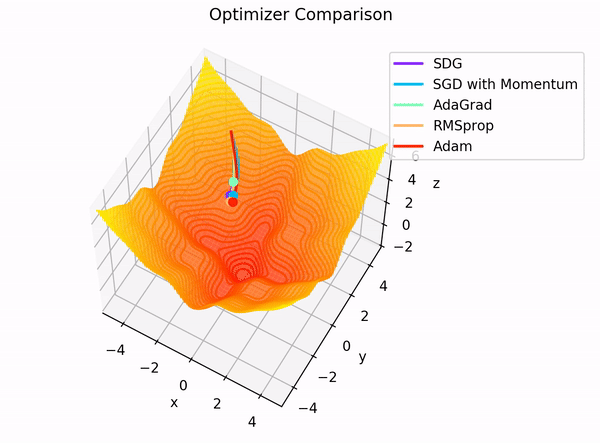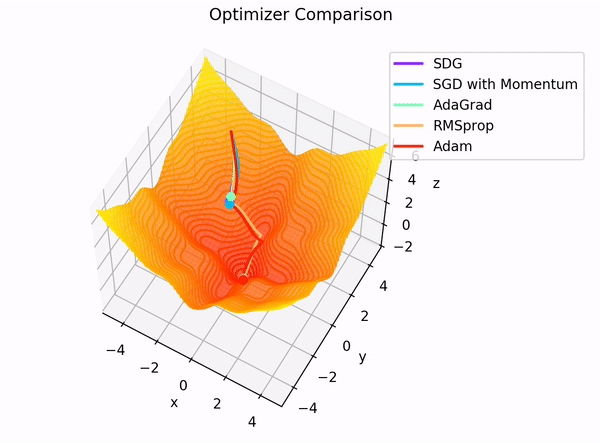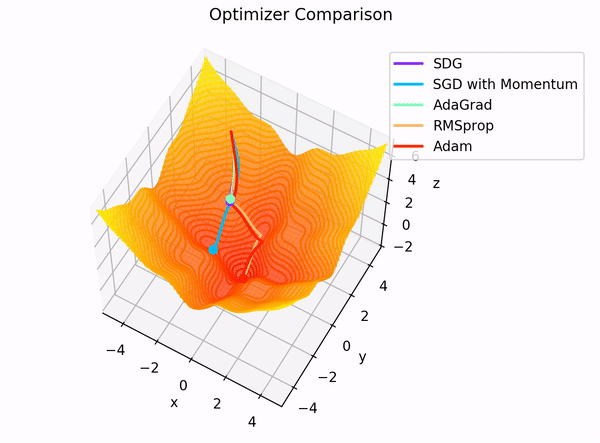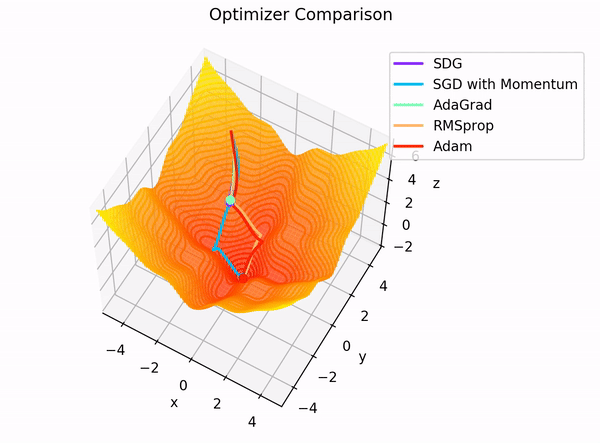
Optimizers are algorithms or methods used to adjust the weights and biases of neural networks to minimize the loss function during training. They determine how the model learns from the data by updating the model parameters in response to the calculated gradients.
Adam (Adaptive Moment Estimation) is one of the most popular optimization algorithms used in training deep learning models, including BERT. It combines the advantages of two other extensions of stochastic gradient descent:
AdaGrad: Maintains per-parameter learning rates that are adapted based on the frequency of updates for each parameter.
RMSProp: Adapts the learning rate based on a moving average of recent gradients.
Evaluating the Model
We evaluate the model on the validation set. Accuracy, precision, recall, and F1 score are common metrics for classification tasks.
- Accuracy: Indicates overall correctness. High accuracy means the model predicts the correct label most of the time.
- Precision: High precision means that when the model predicts a class, it is often correct.
- Recall: High recall means the model successfully finds most of the instances of a class.
- F1 Score: Balances precision and recall; useful when classes are imbalanced.
Making predictions
We define a function to make predictions on new text inputs.
Model Performance and Research Directions
I won’t delve into the details of our model’s prediction accuracy here, but our dataset provides ample opportunities for various studies. As a result, we are working on several research projects we aim to publish.
In addition to the BERT-based model mentioned earlier, we also incorporated a model built using GPT, one of the widely used large language models (LLMs). This approach is discussed in detail in our thesis. The thesis was prepared in Turkish, and you can access the draft version here.